



https://t.co/WPZ31vKIOx
— Luke Igel (@lukeigel) December 20, 2025
Made with the one and only @rtwlz , plus a last-minute army of friends late last night.
All document processing covered by the amazing people at @reductoai ! pic.twitter.com/vloLIklEuY
“Vibe coders” are currently rebuilding the most popular apps on the internet for one specific purpose: making the Jeffrey Epstein document dump searchable. We’re seeing a massive wave of developers using AI tools to turn raw, messy data into slick, familiar interfaces.
The project is centered around Jmail.world, a hub that recreates the Google suite to house thousands of leaked emails and photos. I’m honestly impressed by how fast this moved. It feels like the tech community on X pivoted to this overnight, using AI to wrap disturbing data in the UX of platforms we use every day.
It’s a far cry from how these things used to work. If you think back to the early 2010s, document leaks were usually just massive piles of unsearchable PDFs. Now, anyone with a “vibe coding” setup and an LLM can build a custom search engine in a single afternoon.
The effort is led by developers Riley Walz and Luke Igel, who collaborated with the team at Reducto.ai for the heavy lifting. Reducto.ai provided the extraction tools to turn scanned, blurry PDFs into structured JSON data. This allowed the duo to “vibe code” their way through the clunky Department of Justice files and ship a working product in hours.
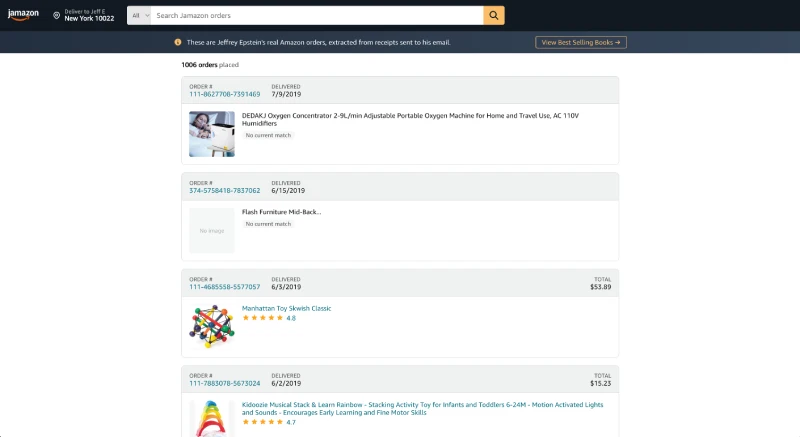
One of the most striking examples is JPhotos, a clone of Google Photos that pulls in over a thousand images from the files. The UI looks remarkably like the real thing, featuring a clean grid of thumbnails showing everything from mansion interiors to evidence documents.
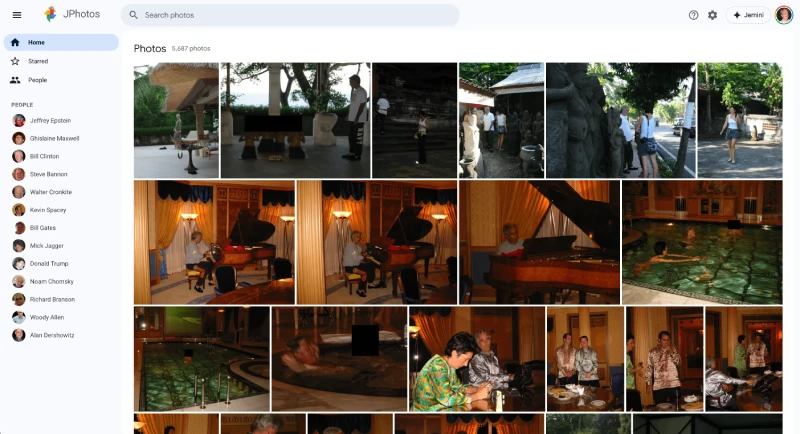
The suite also includes JFlights, which looks like a professional flight tracking dashboard. It catalogs a staggering 4,297 flights and over 10,352 hours of flight time. You can filter by year, specific aircraft like N212JE or N908JE, and even toggle between “Just Jeffrey” or flights with guests. It’s an incredibly detailed look at the movement of his fleet over two decades.
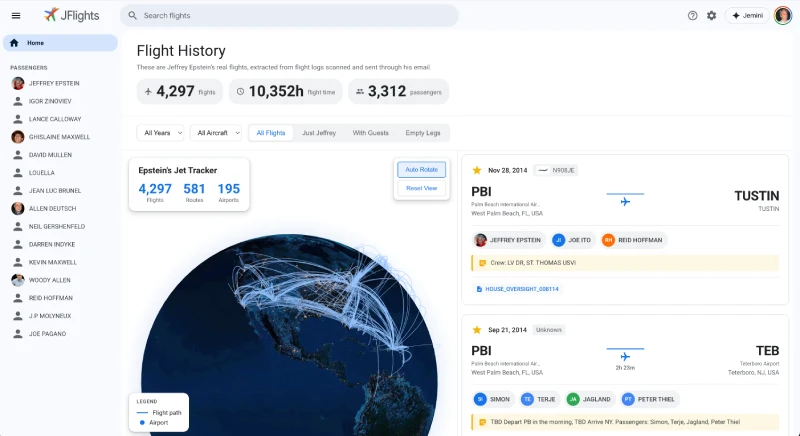
We’ve also seen JDrive, a Google Drive replica where the search function actually works across the entire 300-gigabyte corpus.
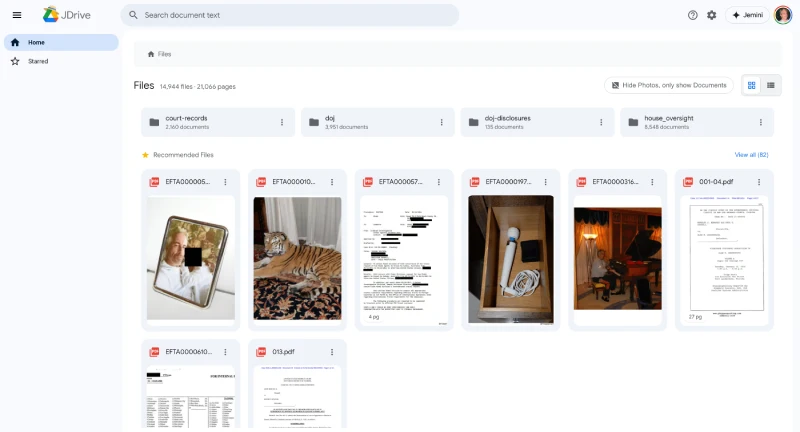
It’s joined by JAmazon, which recreates Epstein’s order history. The interface resembles a standard Amazon order history page, listing mundane purchases such as electronics and books alongside product images and timestamps.
Now, developers are adding even more specialized tools to the mix. X user Pat Dennis just released a powerful facial recognition search that scans the files for specific individuals. It’s an open source project available on GitHub that handles the heavy lifting of turning PDF pages into searchable image data.
search epstein files by image of a face https://t.co/JZVVFUKRYu pic.twitter.com/6zBjBgQynB
— Pat Dennis (@patdennis) December 21, 2025
Interestingly, Dennis didn’t stop at the Epstein files. He’s already expanded the tool to include a January 6th face search, scraping images from the Sedition Hunters website.
Other creators are getting even more experimental with the data. For instance, Advait Paliwal built an Apple Music clone to act as a player for grand jury transcripts. And they’re even in touch with Jmail creators to get their creation featured in the Jmail suite.
I cloned Apple Music, except it's Epstein's grand jury pic.twitter.com/3IMW8vDQaR
— Advait Paliwal (@advaitpaliwal) December 21, 2025
Meanwhile, Diego from Krea AI created EpsteinVR. This 3D tour lets users walk through the financier’s mansion in a way that feels like exploring a video game level. And this too is apparently coming to the Jmail suite soon.
Introducing EpsteinVR: A full 3D model of Jeffrey's Upper East Side mansion (and more), generated using Apple's new SHARP Gaussian Splat model.
— diego (@asciidiego) December 21, 2025
Coming soon to Jmail Suite at jmail . world https://t.co/1AL2INpkBy pic.twitter.com/0I05tOOVY4
We’ll likely see more of these “parody” tools as more documents are released. It’s a strange moment for tech, but it proves that rapid AI development can democratize even the most gatekept information. I’m curious to see if this “vibe coding” approach becomes the new standard for every major public document dump.
That said, feel free to share your thoughts on this approach to make public documents more easily accessible in the comments below.

Dwayne Cubbins
1856 Posts
My fascination with Android phones began the moment I got my hands on one. Since then, I've been on a journey to decode the ever-evolving tech landscape, fueled by a passion for both the "how" and the "why." Since 2018, I've been crafting content that empowers users and demystifies the tech world. From in-depth how-to guides that unlock your phone's potential to breaking news based on original research, I strive to make tech accessible and engaging.